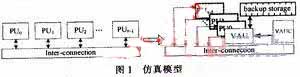
1 對稱多核體系結構FPGA仿真模型
對稱多核如SMP(Symmetry Multi-Processor)體系結構中,通常包含多個對稱的處理器核或計算核心,這里統稱為計算核。計算核占據了多核體系結構的主要硬件開銷,且對稱多核體系結構的硬件仿真平臺FPGA資源消耗隨計算核數目成線性增加。這里提出的對稱多核體系結構FPGA仿真模型,解耦合計算核數目與系統硬件開銷的線性關系,其核心設計思想是:在構建仿真系統時,使用一個與目標系統中單個計算核等同的處理單元,稱為虛擬計算單元VAU(Virtual Arithmetic Unit)代替所有的對稱計算核,通過分時復用VAU實現一個計算單元虛擬多個計算核的行為。
圖l中的左圖是當前具有對稱結構的多核體系結構模型抽象,n個對稱的計算核通過特定的互連結構連接,其連接關系由目標處理器的工作模式決定;右圖是本文提出的仿真模型。可以看出,仿真系統中采用一個VAU代替了目標系統中所有對稱的處理單元PU。在對目標系統進行仿真時,計算頁控制器VAUC(VAU Controller)控制1個VAU分時復用的方式工作,虛擬多個PU并行執行。分時的粒度與處理單元之間的耦合度相關。虛擬計算單元將目標系統中并行執行模式轉變為串行執行的方式進行仿真,以時間換取空間,減少系統中計算資源的消耗。BS(Backup Storage)用于存儲VAU虛擬各PU執行時的中間結果。
2 仿真系統執行模式
2.1 多核/眾核體系結構仿真系統執行模式
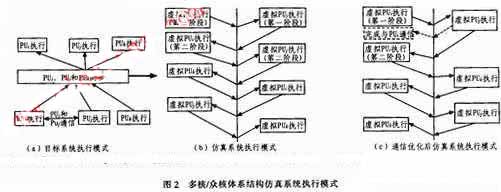
對稱多核處理器中處理單元之間的耦合度不同,使得對應的仿真系統的執行模式也不一樣。多核/眾核體系結構通常采用粗粒度耦合執行的方式。如圖2(a)所示.多個處理單元之間相互比較獨立,其同步和通信通常處于任務級,即多個處理單元間的通信和同步的次數遠小于它們執行的指令數。圖中PUi和PUj之間有一次通信,PUi、PUj和PUk之間有一次同步。對應的仿真系統的執行模式如圖2(b)所示,VAU先對PUi進行仿真,執行到與通信點時,將PUi的執行信息導入BS,然后VAU對PUi進行仿真,執行到與通信點時,將PUj的執行信息導入BS,將PUi的執行信息由BS導入VMU,對PUi的后續行為進行仿真,以此類推,如圖2所示,箭頭每穿過中線一次,表示計算頁切換一次仿真對象,指向下的箭頭表示VMU的信息導入BS,指向上的箭頭表示BS中的信息導出至VMU。為了減少現場切換的次數,對兩個PU通信時的執行過程進行優化,如圖2(c)所示,VAU仿真PUi執行至通信點時,切換至PUj進行仿真,只有在PUj遇到其他同步或通信時,才進行現場切換,否則VAU一直對PUj進行仿真,直至PUj執行結束。PUj執行到與通信點時,PUj將通信數據發送至網絡緩沖,并寫入PUi對應的存儲空間,如圖2(c)中虛線所示。
2.2 SIMD體系結構仿真系統執行模式
SIMD體系結構的處理單元之間是緊密耦合的,所有處理單元的執行過程都是嚴格同步的,即同一時鐘周期內每個處理單元都對不同的數據進行完全同樣的操作,如圖3(a)所示。

在SIMD體系結構仿真系統中,必須在邏輯上保持這種完全同步的執行模式。本文采用的方式是,一條指令流出之后,讓它在指令流水線中保持n個時鐘周期(可以在連續的n個時鐘內都發射同一條指令),VAU在這n個周期內分別對各處理單元對應的數據進行處理。若將n個時鐘周期看作系統的工作周期,則n個數據是在同一工作周期內被處理,如圖3(b)所示。這樣則在邏輯上保持SIMD的執行模式。
3 仿真系統評估
本文的目標系統如圖4(a)所示。它由多個計算節點以Torus片上網絡連接構成,其計算節點數目可以根據應用需求進行擴展。對應的仿真系統如圖4(b)所示。在仿真系統中,采用一個虛擬計算節點(VAU)代替目標系統中的p個計算節點,圖4(b)以p=4為例,展示了仿真系統的結構。目標系統中p個計算節點的計算操作都由VAU以圖2的工作模式完成。VAU中包含一個現場保存存儲器(context backup),用于保存目標系統中p個計算節點的中間結果。contextbackup的容量為每個計算節點中本地存儲器容量的p倍,這樣,context backup就有足夠的能力存儲p個計算節點的中間結果,從而減少與外部存儲器的數據交換,減少VAU的停頓時間。
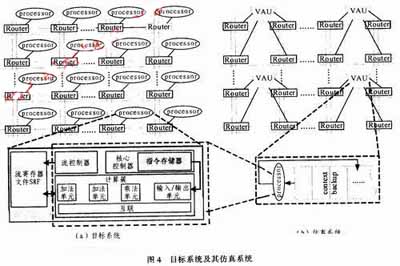
采用FPGA EP2S180(擁有143 520 ALUT,相當于18萬邏輯門)實現了多種結構(計算節點的數目不同)的目標系統和基于仿真模型的仿真系統,并利用相應的硬件綜合工具Quartus分析仿真系統的FPGA資源開銷。系統采用包含1個cluster的MASA流處理器作為計算節點。為更好地驗證仿真模型,流處理器中采用功能裁剪的cluster,如圖4所示,cluster中僅包含3個計算單元和1個I/O單元,并相應降低指令和數據存儲器的容量。在仿真系統中,VAU中的processor為流處理器中的核心計算部件,context backup代替了片上存儲部件,其容量為SRF的p倍。該實驗的目的是分析所提出的仿真模型對仿真系統的硬件資源消耗和仿真速度的影響。
3.1 資源消耗分析
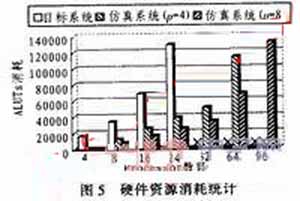
圖5是目標系統和仿真系統的FPGA資源消耗統計。由于布局布線的需求,FPGA芯片的資源使用率最高通常只能達到70%~80%。圖5中“×”標識表示當前配置超出EP2S180的仿真能力。可以看出,在不采用仿真優化技術時,EP2S180可仿真的最大規模目標系統為24個計算節點。基于本文的仿真模型,當p值等于4時,EP2S180的仿真能力提高至64個節點;當p值等于8時,其仿真能力提高至96個節點。當p值增大時,其仿真能力可進一步提升。實驗結果表明,本文提出的仿真模型能夠增大FPGA芯片可仿真系統的規模。
3.2 仿真速度分析
本文采用矩陣乘運算,分別在8、16、32個節點的目標系統和仿真系統上執行,測試二者的仿真速度。目標系統和仿真系統的工作頻率為75 MHz。圖6展示了二者的執行時間。
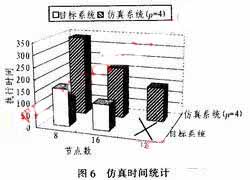
可以看出,仿真系統的執行時間大于目標系統。其時間增量主要是由于仿真系統將目標系統中多個processor并行處理的任務移植到一個VAU上串行執行造成。仿真系統沒有改變目標系統的數據傳輸路徑和模式,因此,數據傳輸的時間并沒有增加。另外,由于VAU虛擬的p個pro-cessor共享了存儲空間,仿真系統中消除了p個processor之間的數據傳輸時間。雖然仿真系統相對于目標系統執行時間有所增加,但其時間增量處于秒級。相對于緩慢的軟件模擬器,并綜合考慮仿真模型對FPGA仿真規模帶來的好處,因此認為該仿真模型帶來的仿真時間增量是可以接受的。
4 結束語
本文提出了面向對稱多核體系結構的FPGA仿真模型,以及基于該模型的多核/眾核、SIMD體系結構的執行模式。相對于軟硬件聯合仿真方法,該仿真模型減少了軟硬件協同邏輯并避免了設計復雜的軟件劃分算法。實驗結果表明,面向對稱多核體系結構的FPGA仿真模型能有效地減少仿真系統FPGA資源的需求,增大FPGA的仿真規模,并且其帶來的仿真時間增量是可接受的。但該仿真模型主要是面向對稱體系結構,而不適用于異構多核系統等非對稱結構。
聲明:本內容為作者獨立觀點,不代表電源網。本網站原創內容,如需轉載,請注明出處;本網站轉載的內容(文章、圖片、視頻)等資料版權歸原作者所有。如我們采用了您不宜公開的文章或圖片,未能及時和您確認,避免給雙方造成不必要的經濟損失,請電郵聯系我們,以便迅速采取適當處理措施;歡迎投稿,郵箱∶editor@netbroad.com。
| 微信關注 | ||
 |
| 技術專題 | 更多>> | |
 |
| 技術專題之EMC |
 |
| 技術專題之PCB |



| 電子行業原創技術內容推薦 | |
 |


互聯網違法不良信息舉報
Reporting Internet Illegal and Bad Information editor@netbroad.com
editor@netbroad.com
 400-003-2006
400-003-2006





















