

近日筆者在閱讀Shift-GCN[2]的文獻,Shift-GCN是在傳統的GCN的基礎上,用Shift卷積算子[1]取代傳統卷積算子而誕生出來的,可以用更少的參數量和計算量達到更好的模型性能,筆者感覺蠻有意思的,特在此筆記。 本文轉載自徐飛翔的“Shift-GCN網絡論文筆記”
版權聲明:本文為博主原創文章,遵循 CC 4.0 BY-SA 版權協議,轉載請附上原文出處鏈接和本聲明。
Shift-GCN是用于骨骼點序列動作識別的網絡,為了講明其提出的背景,有必要先對ST-GCN網絡進行一定的了解。
ST-GCN網絡
骨骼點序列數據是一種天然的時空圖結構數據,具體分析可見[5,6],針對于這類型的數據,可以用時空圖卷積進行建模,如ST-GCN[4]模型就是一個很好的代表。簡單來說,ST-GCN是在空間域上采用圖卷積的方式建模,時間域上用一維卷積進行建模。
骨骼點序列可以形式化表達為一個時空圖,其中有著
個關節點和
幀。骨骼點序列的輸入可以表達為
,其中
表示維度。為了表示人體關節點之間的連接,我們用鄰接矩陣表達。按照ST-GCN原論文的策略,將人體的鄰接矩陣劃分為三大部分:1)離心群;2)向心群;3)根節點。具體的細節請參考論文[4]。每個部分都對應著其特定的鄰接矩陣
,
其中
表示劃分部分的索引。用符號
和
分別表示輸入和輸出的特征矩陣,其中
和
是輸入輸出的通道維度。那么,根據我們之前在GCN系列博文[7,8,9]中介紹過的,我們有最終的人體三大劃分的特征融合為:
其中P = { 根 節 點 , 離 心 群 , 向 心 群 } ,是標準化后的鄰接矩陣,其中
,具體這些公式的推導,見[7,8,9]。其中的
是每個人體劃分部分的1x1卷積核的參數,需要算法學習得出。整個過程如Fig 1.1所示。

ST-GCN的缺點體現在幾方面:
- 計算量大,對于一個樣本而言,ST-GCN的計算量在16.2GFLOPs,其中包括4.0GFLOPs的空間域圖卷積操作和12.2GFLOPs的時間一維卷積操作。
- ST-GCN的空間和時間感知野都是固定而且需要人為預先設置的,有些工作嘗試采用可以由網絡學習的鄰接矩陣的圖神經網絡去進行建模[10,11],即便如此,網絡的表達能力還是受到了傳統的GCN的結構限制。
Shift-GCN針對這兩個缺點進行了改進。
Shift-GCN
這一章對Shift-GCN進行介紹,Shift-GCN對ST-GCN的改進體現在對于空間信息(也就是單幀的信息)的圖卷積改進,以及時序建模手段的改進(之前的工作是采用一維卷積進行建模的)。
Spatial Shift-GCN
Shift-GCN是對ST-GCN的改進,其啟發自Shift卷積算子[1],主要想法是利用1x1卷積算子結合空間shift操作,使得1x1卷積同時可融合空間域和通道域的信息,具體關于shift卷積算子的介紹見博文[12],此處不再贅述,采用shift卷積可以大幅度地減少參數量和計算量。如Fig 2.1所示,對于單幀而言,類似于傳統的Shift操作,可以分為Graph Shift和1x1 conv兩個階段。然而,和傳統Shift操作不同的是,之前Shift應用在圖片數據上,這種數據是典型的歐幾里德結構數據[7],數據節點的鄰居節點可以很容易定義出來,因此卷積操作也很容易定義。而圖數據的特點決定了其某個數據節點的鄰居數量(也即是“度”)都可能不同,因此傳統的卷積在圖數據上并不管用,傳統的shift卷積操作也同樣并不能直接在骨骼點數據上應用。那么就需要重新在骨骼點數據上定義shift卷積操作。
作者在[2]中提出了兩種類型的骨骼點Shift卷積操作,分別是:
- 局部Shift圖卷積(Local Shift Graph Convolution)
- 全局Shift圖卷積(Global Shift Graph Convolution)
下文進行簡單介紹。
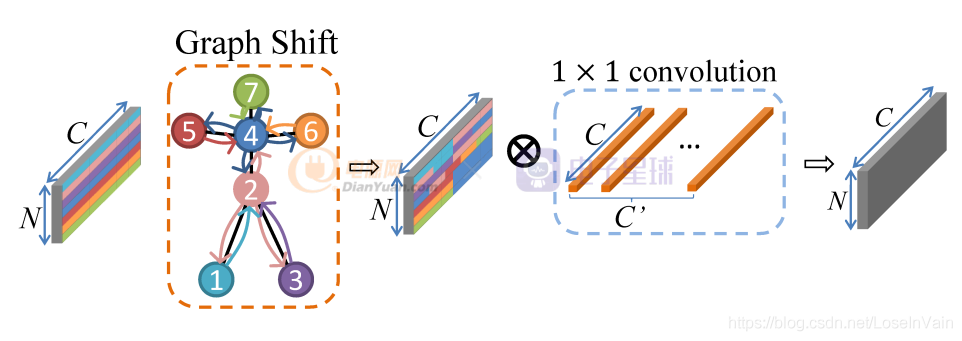
局部shift圖卷積
在局部shift圖卷積中,依然只是考慮了骨骼點的固有物理連接,這種連接關系與不同數據集的定義有關,具體示例可見博文[13],顯然這并不是最優的,因為很可能某些動作會存在節點之間的“超距”關系,舉個例子,“拍掌”和“看書”這兩個動作更多取決于雙手的距離之間的變化關系,而雙手在物理連接上并沒有直接相連。
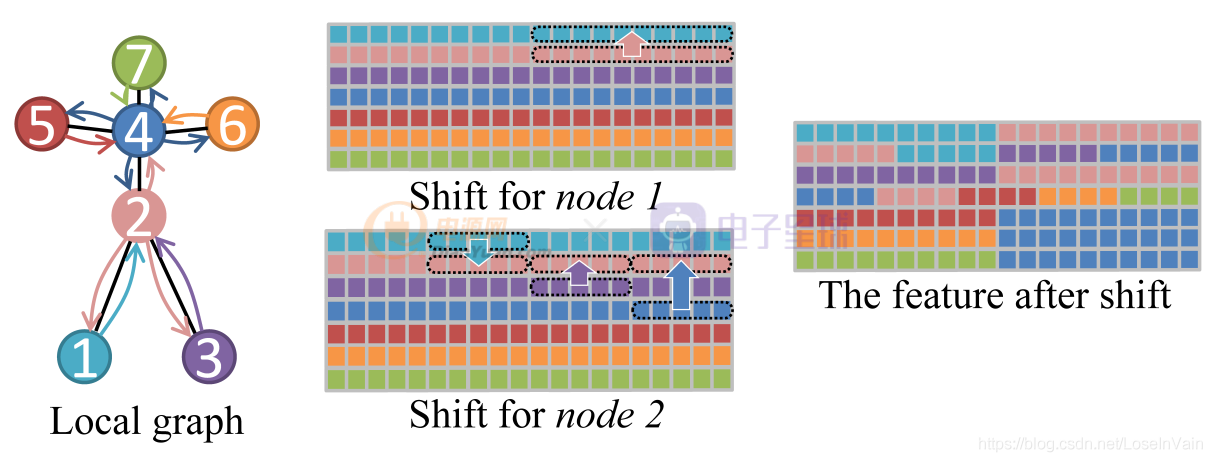
盡管局部shift圖卷積只考慮骨骼點的固有連接,但是作為一個好的基線,也是一個很好的嘗試,我們開始討論如何定義局部shift圖卷積。如Fig 2.2所示,為了簡便,我們假設一個骨架的骨骼點只有7個,連接方式如圖所示,不同顏色代表不同的節點。對于其中某個節點 ,
而言,用
表示節點v vv的鄰居節點,其中
是
鄰居節點的數量。類似于傳統的Shift卷積中所做的,對于每一個節點的特征向量
,其中
是通道的數量,我們將通道均勻劃分為
份片區,也即是每一份片區包含有
個通道。我們讓第一份片區保留本節點(也即是
節點本身)的特征,而剩下的
個片區分別從鄰居
中通過平移(shift)操作得到,如式子(2.1)所示。用
表示單幀的特征,用
表示圖數據shift操作之后的對應特征,其中
表示節點的數量,
表示特征的維度,本例子中
。
整個例子的示意圖如Fig 2.2所示,其中不同顏色的節點和方塊代表了不同的節點和對應的特征。以節點1和節點2的shift操作為例子,節點1的鄰居只有節點2,因此把節點1的特征向量均勻劃分為2個片區,第一個片區保持其本身的特征,而片區2則是從其對應的鄰居,節點2中的特征中平移過去,如Fig 2.2的Shift for node 1所示。類似的,以節點2為例子,節點2的鄰居有節點4,節點1,節點3,因此把特征向量均勻劃分為4個片區,同樣第一個片區保持其本身的特征,其他鄰居節點按照序號升序排列,片區2則由排列后的第一個節點,也就是節點1的特征平移得到。類似的,片區3和片區4分別由節點3和節點4的對應片區特征平移得到。如Fig 2.2的Shift for node 2所示。最終對所有的節點都進行如下操作后,我們有如Fig 2.2的The feature after shift所示。
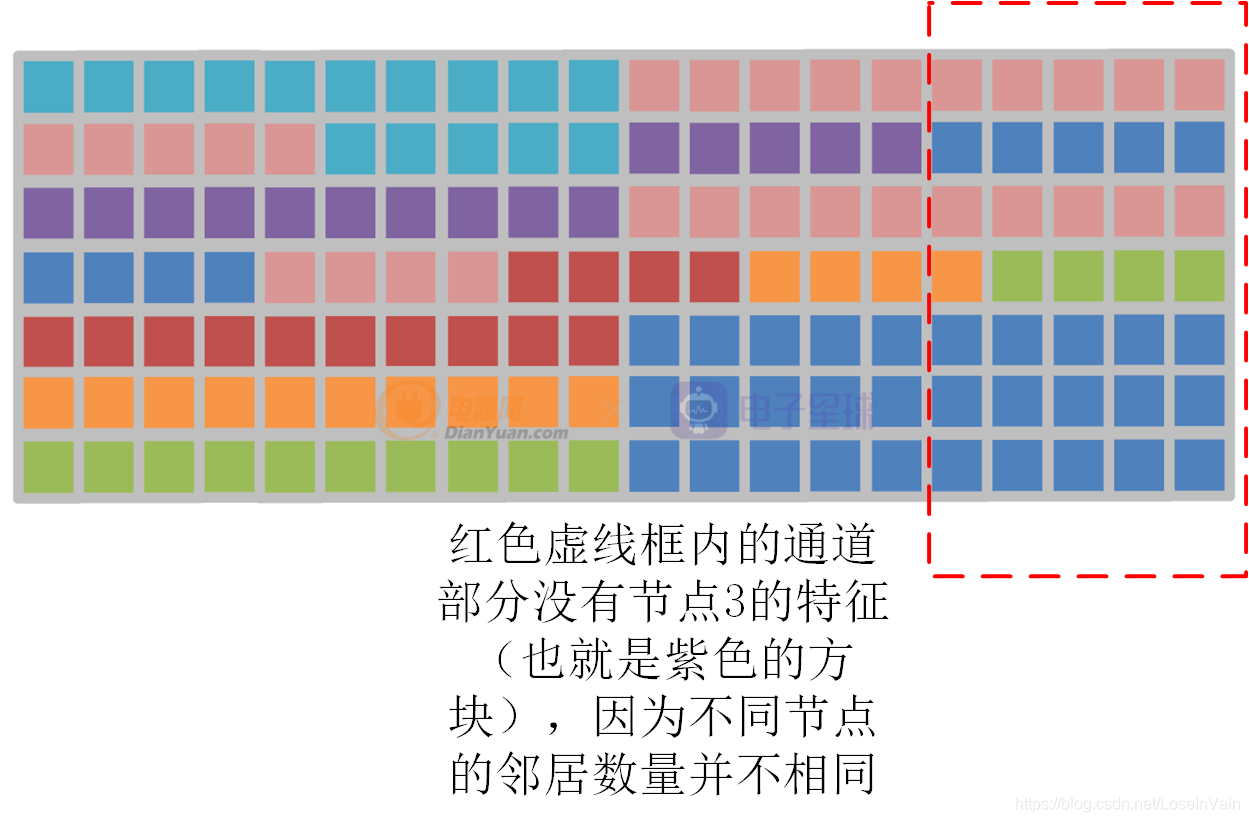
全局shift圖卷積
局部shift圖卷積操作有兩個缺點:
- 只考慮物理固有連接,難以挖掘潛在的“超距”作用的關系。
- 數據有可能不能被完全被利用,如Fig 2.2的節點3的特征為例子,如Fig 2.3所示,節點3的信息在某些通道遺失了,這是因為不同節點的鄰居數量不同。
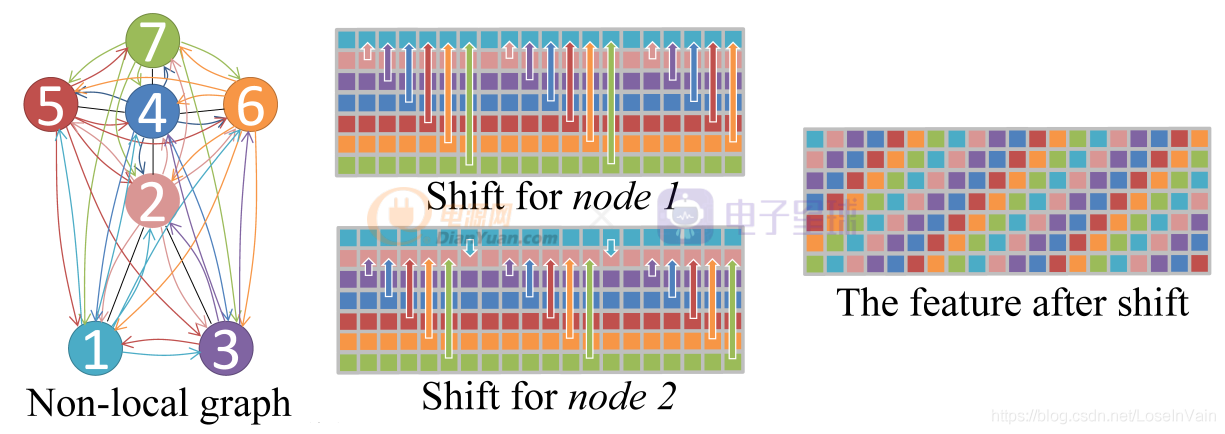
為了解決這些問題,作者提出了全局Shift圖卷積,如Fig 2.4所示。其改進很簡單,就是去除掉物理固有連接的限制,將單幀的骨骼圖變成完全圖,因此每個節點都會和其他任意節點之間存在直接關聯。給定特征圖,對于第i ii個通道的平移距離
。這樣會形成類似于螺旋狀的特征結構,如Fig 2.4的The feature after shift所示。
為了挖掘骨骼完全圖中的人體關鍵信息,把重要的連接給提取出來,作者在全局shift圖卷積基礎上還使用了注意力機制,如式子(2.2)所示。
Temporal Shift-GCN
在空間域上的shift圖卷積定義已經討論過了,接下來討論在時間域上的shift圖卷積定義。如Fig 2.5所示,考慮到了時序之后的特征圖層疊結果,用符號表示時空特征圖,其中有
。這種特征圖可以天然地使用傳統的Shift卷積算子,具體過程見[12],我們稱之為naive temporal shift graph convolution。在這種策略中,我們需要將通道均勻劃分為
個片區,每個片區有著偏移量為
。與[12]策略一樣,移出去的通道就被舍棄了,用0去填充空白的通道。這種策略需要指定u uu的大小,涉及到了人工的設計,因此作者提出了adaptive temporal shift graph convolution,是一種自適應的時序shift圖卷積,其對于每個通道,都需要學習出一個可學習的時間偏移參數
。如果該參數是整數,那么無法傳遞梯度,因此需要放松整數限制,將其放寬到實數,利用線性插值的方式進行插值計算,如式子(2.3)所示。
其中是由于將整數實數化之后產生的余量,需要用插值的手段進行彌補,由于實數化后,錨點落在了
之間,因此在這個區間之間進行插值。

網絡
結合spatial shift-gcn和temporal shift-gcn操作后,其網絡基本單元類似于ST-GCN的設計,如Fig 2.6所示。

Update 20201130:來自一個知乎朋友的問題:
ID:fightingQ:好巧啊,又跟你看到同一篇論文了。不知道還記得我嗎。這里的naive temporal shift 寫的不詳細。不知道我理解的對不對,想跟你探討一下。對于每一個節點的c個通道,劃分為u個部分。每個部分分別替換為其第-u,,,0,1,u幀處的對應特征,其中0指的是節點本身的這一部分特征。這樣每一個節點就會包含了2u+1幀的信息。在adaptive中,每個通道都設置了一個可學習的移動參數,但是這個移動參數是怎么來學的。我隨意設置這樣一個學習的shift參數,學習的依據是啥呢?
回答:正如原文所講的,其中的naive temporal shift完全是按照傳統的shift卷積算子操作進行計算的,具體見[1]。我們知道,進行通道上的shift操作的目的在于改變卷積的感知野,因此文中提到的超參數其實就是控制了每一層的時序感知野大小,但是這樣有幾個缺點:
- 卷積是具有層次結構的,每一層的u uu如果都一樣,那么感知野理論上也是一樣的,這樣不合理,因此卷積的層次結構意味著感知野大小不一定一致。
- 需要人工去設置這個超參數
,對于不同數據集的結果都不一樣,工作量大。
因此,引入了所謂的自適應時序 shift,其出發點就是通過反向梯度傳播去學習每一層的感知野,也就是每一層都有一個,因為需要確保可以求導,這個參數必須是保證為浮點數才能存在梯度,因此shift操作被泛化到插值操作,正如式子(2.3)所示。
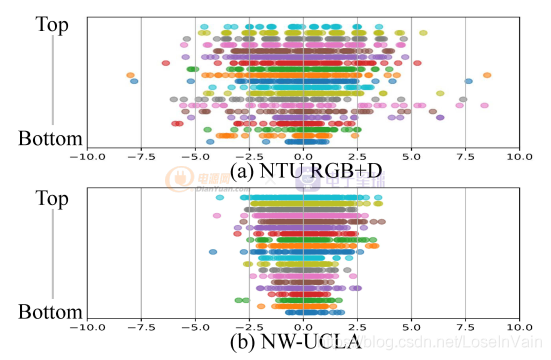
其實原論文對這個自適應學習出來的參數進行了可視化,如Fig a1所示,作者對于不同的數據集(NTU RGBD和NW-UCLA)上進行了adaptive temporal shift的每一層的結果的可視化(具體分析見原論文),簡單來說,頂層(top layer, 也即是輸出層)的值范圍都比較大(表現為值的范圍比較寬廣),意味著輸出層需要的時序感知野比較大,這一點很容易理解,因為輸出層需要更多的時序語義信息,因此感知野比較大是正常的;而底層(bottom layer,也即是輸入層)的值范圍都比較小,這一點也很好理解,輸入層更多的是單幀的底層信息建模(比如紋理,色彩,邊緣信息等),因此時序感知野比較小是正常的。
通過這種自適應的學習手段,確保了對不同層的shift系數的獨立學習,因此使得不同層具有不同的時序感知野。
以上。
Reference
[1]. Wu, B., Wan, A., Yue, X., Jin, P., Zhao, S., Golmant, N., … & Keutzer, K. (2018). Shift: A zero flop, zero parameter alternative to spatial convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 9127-9135).
[2]. Cheng, K., Zhang, Y., He, X., Chen, W., Cheng, J., & Lu, H. (2020). Skeleton-Based Action Recognition With Shift Graph Convolutional Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 183-192).
[3]. https://fesian.blog.csdn.net/article/details/109474701
[4]. Sijie Yan, Yuanjun Xiong, and Dahua Lin. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
[5]. https://fesian.blog.csdn.net/article/details/105545703
[6]. https://blog.csdn.net/LoseInVain/article/details/87901764
[7]. https://blog.csdn.net/LoseInVain/article/details/88373506
[8]. https://fesian.blog.csdn.net/article/details/90171863
[9]. https://fesian.blog.csdn.net/article/details/90348807
[10]. Lei Shi, Yifan Zhang, Jian Cheng, and Hanqing Lu. Skeleton-based action recognition with directed graph neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7912–7921, 2019
[11]. Lei Shi, Yifan Zhang, Jian Cheng, and Hanqing Lu. Two stream adaptive graph convolutional networks for skeleton based action recognition. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
[12]. https://fesian.blog.csdn.net/article/details/109474701
[13]. https://fesian.blog.csdn.net/article/details/108242717